Survey link on Arxiv: Link
Abstract
Recent advancements in conversational systems have significantly enhanced human-machine interactions across various domains. However, training these systems is challenging due to the scarcity of specialized dialogue data. Traditionally, conversational datasets were created through crowdsourcing, but this method has proven costly, limited in scale, and labor-intensive. As a solution, the development of synthetic dialogue data has emerged, utilizing techniques to augment existing datasets or convert textual resources into conversational formats, providing a more efficient and scalable approach to dataset creation. In this survey, we offer a systematic and comprehensive review of multi-turn conversational data generation, focusing on three types of dialogue systems: open domain, task-oriented, and information-seeking. We categorize the existing research based on key components like seed data creation, utterance generation, and quality filtering methods, and introduce a general framework that outlines the main principles of conversation data generation systems. Additionally, we examine the evaluation metrics and methods for assessing synthetic conversational data, address current challenges in the field, and explore potential directions for future research. Our goal is to accelerate progress for researchers and practitioners by presenting an overview of state-of-the-art methods and highlighting opportunities to further research in this area.
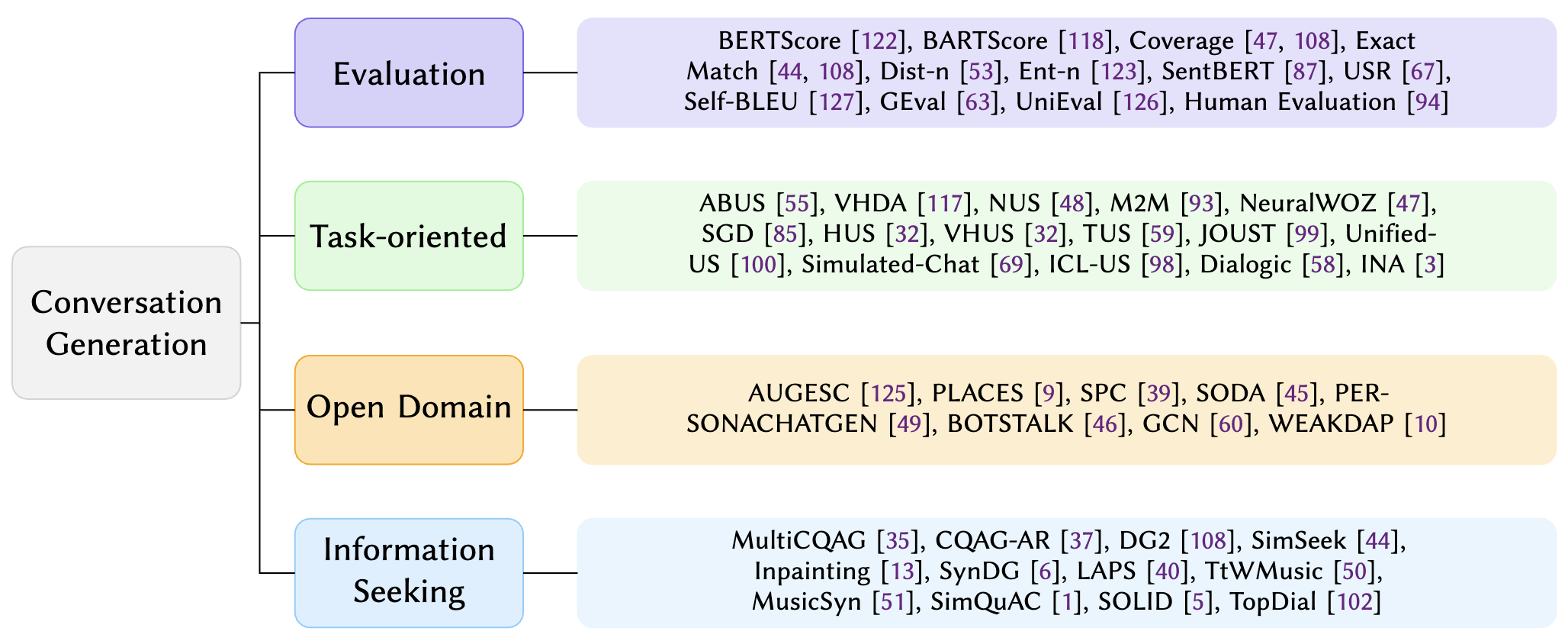
Survey Overview
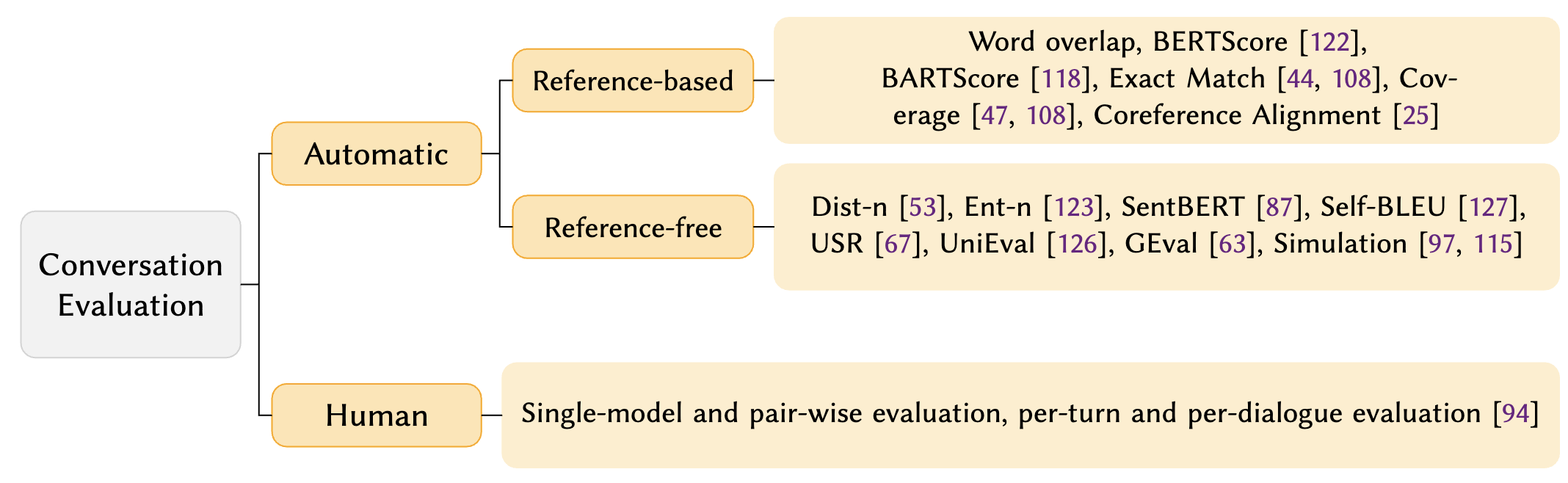
Evaluation Overview
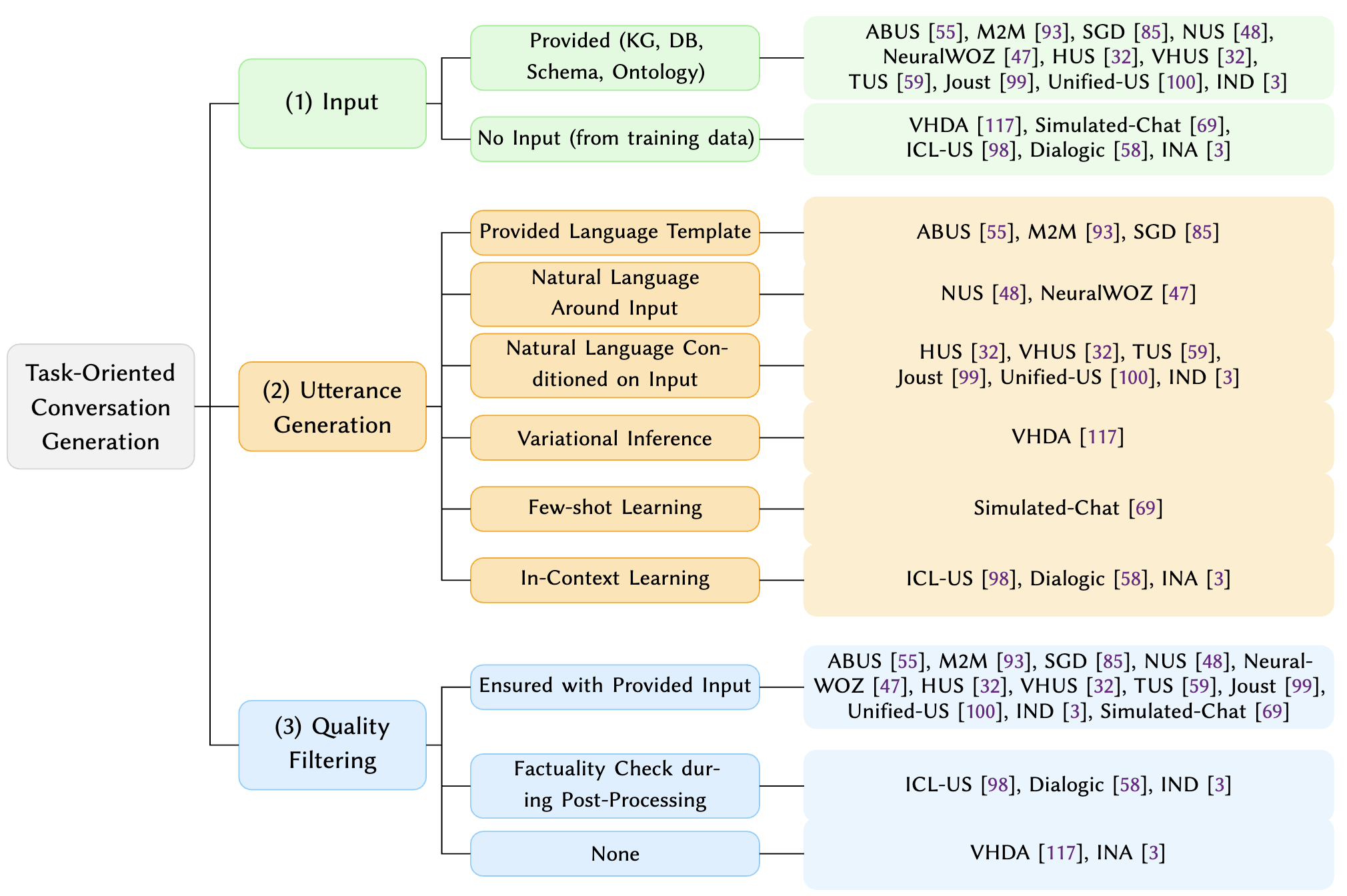
ToD Overview
ODD Overview
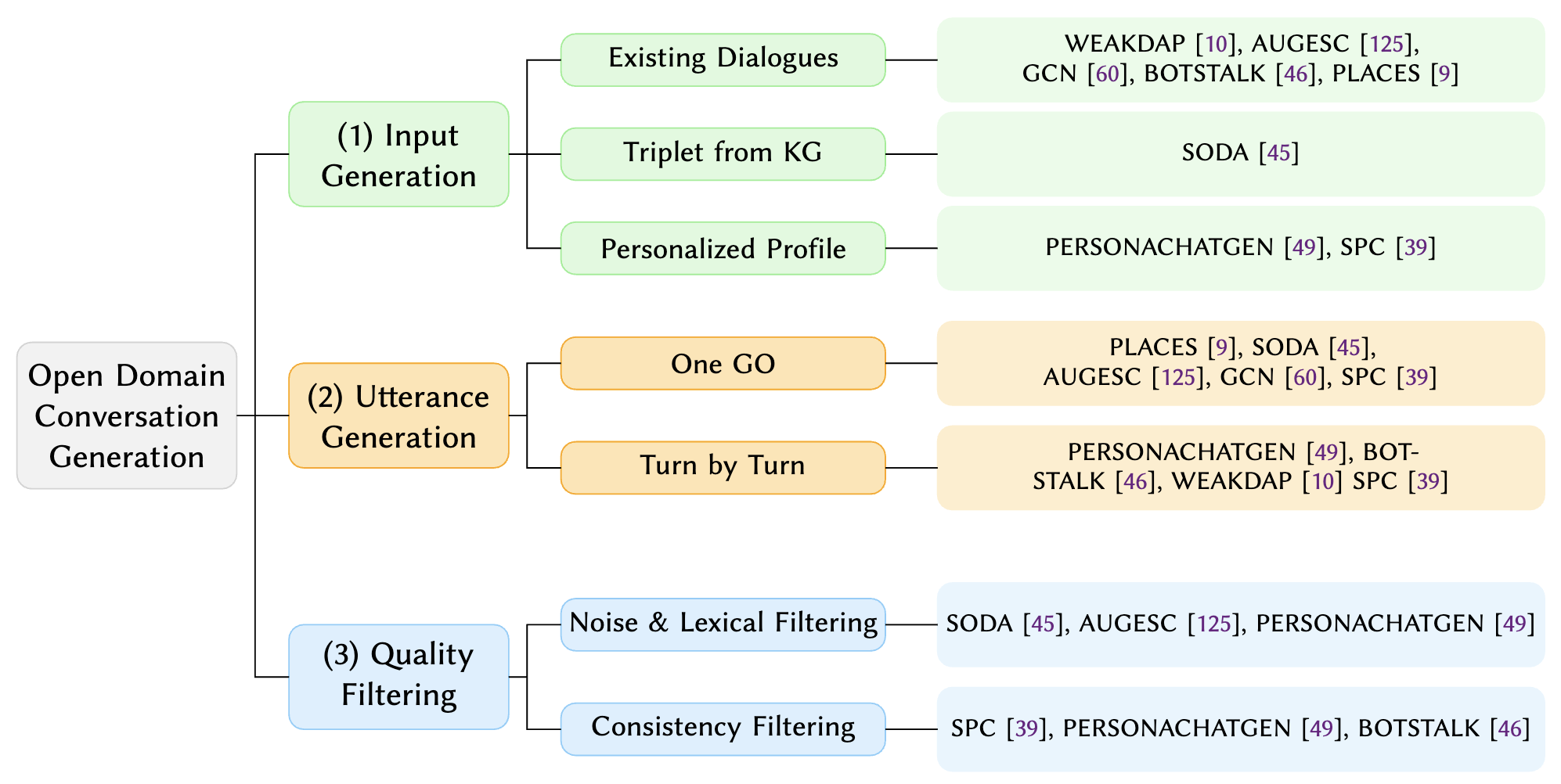
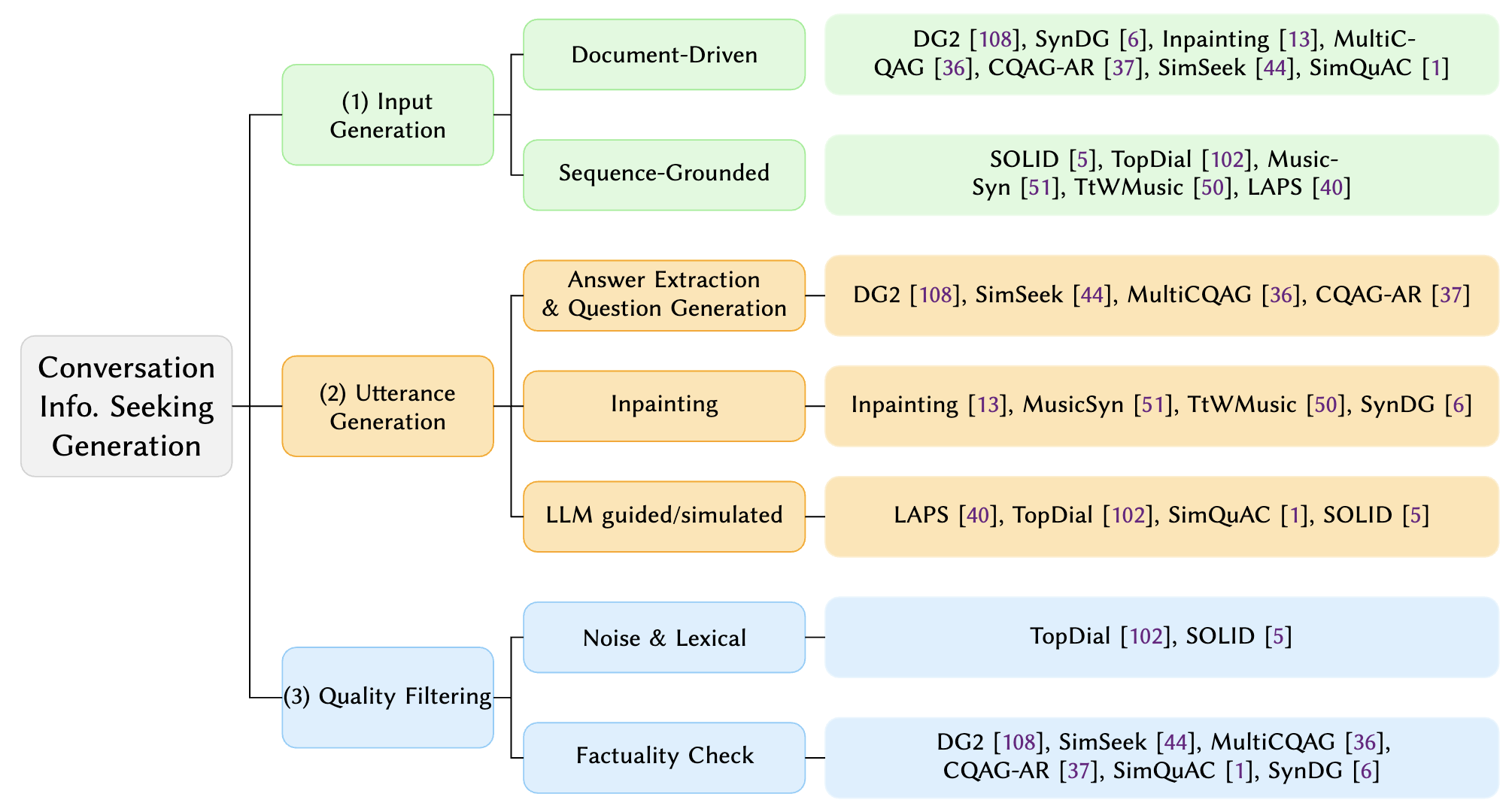
CIS Overview